

DARPA has always been on the forefront of Artificial Intelligence (AI), driving the technology forward. So it’s no surprise that we have some pretty definitive views about where it’s headed. There’s been a lot of hype and bluster about AI, talk about a singularity that will see AI exceeding the capabilities of human beings, and maybe even displace humanity.
We’re going to take a much more level-headed approach and attempt to demystify all this talk about the technology, what it can do, what it can’t do, and where it’s headed. First, it’s helpful to think about three waves of AI technology. The first wave was based on handcrafted knowledge. Here experts took knowledge that they had about a particular domain and they characterized in rules that could fit into a computer, which in turn could study the implications of those rules. Examples of this are logistics programs, scheduling, game playing programs like chess, and even TurboTax. In the case of TurboTax, there are experts who are tax lawyers and tax accountants, who are able to take the complexities of the tax code and turn them into certain rules with which a computer can work.

Artificial intelligence is a programmed ability to process information.
This kind of logical reasoning is very typical of these first wave systems: they’re very good at being able to take the particular facts of a concrete situation and work through them. But they’re not very good at other dimensions of intelligence, dimensions that include, for example, the ability to perceive the outside world and see what’s going on. TurboTax can take your W-2 and make sense of it, but that’s about the limit of it. It’s no good at learning. And learning is a major part of intelligence.

Characteristics of first wave systems.
But neither do these shortcomings mean that these first wave systems are old, tedious, and boring. In fact, we’ve just had some great success this year in cybersecurity where systems based on first wave technologies have been able to study the codes in a computer and make sense of vulnerabilities. DARPA’s recent Cyber Grand Challenge was a great proof that first wave technology is still very relevant.
There is, however, another characteristic of intelligence that we don’t see in these first wave systems: abstraction—the ability to take knowledge discovered at a certain level and apply it up at another level.
First wave systems stumble when it comes to operating in the natural world. We saw this when DARPA was doing a lot of work in self-driving cars in 2004 and 2005. We set a challenge to the automotive community that was developing the technology for self-driving cars to see how they might put this technology together and drive 150 miles in the California and Nevada desert. In 2004, exactly zero cars completed the course. They all failed. In fact, no car went further than eight miles down the course. They found it very difficult at that time for the vision systems distinguish whether a black shape in the distance was a shadow or a rock. Should I avoid it? Should I barrel through it? They kept making the wrong decisions. A year later, though, many cars were successful. In fact, five cars completed the entire course. The big change was that they started to use machine learning; they started to use techniques that were probabilistic in the way that they handled information.

DARPA’s Autonomous Vehicle Grand Challenge called for self-driving vehicles to navigate 150 miles of dirt tracks in California and Nevada. In 2004 no vehicles finished the course; in 2005, five completed it.
This leads us to a second wave of AI technology—a wave characterized by statistical learning. And it’s been tremendously effective in applications like voice recognition, face recognition, sorting through your photos, etc. It’s been so successful that people believe that the computer will just “learn things.” But actually, nothing could be further from the truth. There’s a tremendous amount of effort that goes on behind the scenes to create the statistical models that characterize the problem domain they’re trying to solve. Moreover, they train the statistical models on specific data.

Characteristics of the second wave of AI technology.
The characteristics of these second wave systems is that they’re very good at being able to perceive the natural world—for example, separating one face from another or one vowel sound from a different vowel sound. They’re also very good at learning. By providing them with particular kinds of datasets, they’re able to learn and adapt to different kinds of situations. They’re very strong in these dimensions of intelligence. However, in the strong logical reasoning intelligence that we saw with the first wave systems, the second wave systems have very limited capability. They still give us no new capability to abstract knowledge from one domain and apply it dramatically into another domain. So while second wave technologies have nuanced capabilities to classify data, and even predict consequences of data, they don’t really have any ability to understand the context in which these tasks are taking place. In other words, they have minimal capability to reason.
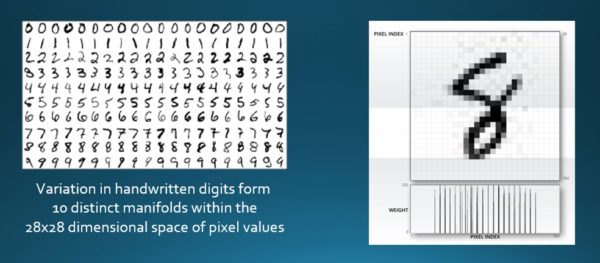
It’s worth digging under the surface a little to understand a bit better why these systems work, and what they’re capable of doing and what they’re not capable of doing. To this end, it’s helpful to touch just a little bit on higher mathematics. There’s something called the manifold hypothesis. A manifold is a structure in geometry, a structure where data is clumped together such that it forms a substructure within a much larger embedding space. It turns out that when we’re dealing with the natural world, the data that we care about forms these clumps.
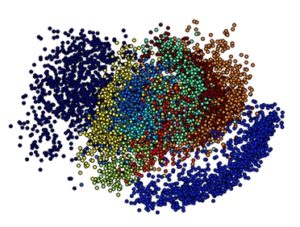 The image at right shows that different kinds of data have clumped together in multiple dimensions. Each of these manifolds represents a different entity. For an AI system to understand the data, it must first separate these different clumps. Now, you can imagine that it’s really hard to describe what distinguishes one clump from another. So second wave technology needs to find a new way to be able to separate these things. It does this by “stretching and squashing” the dataspace.
The image at right shows that different kinds of data have clumped together in multiple dimensions. Each of these manifolds represents a different entity. For an AI system to understand the data, it must first separate these different clumps. Now, you can imagine that it’s really hard to describe what distinguishes one clump from another. So second wave technology needs to find a new way to be able to separate these things. It does this by “stretching and squashing” the dataspace.
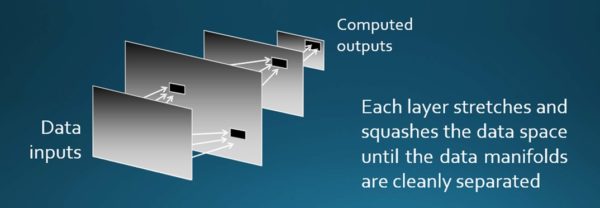
Here’s an example: rather than use lots of dimensions, I’ve reduced the problem to just two dimensions. In the figure, below, you see a blue curve and a red curve. Each of these represents a different manifold of data, a different set of data points. By stretching and squashing it, we’re able to pull these things apart that were intertwined, and yield a clean separation between them. This is what second wave systems do. And for this work, they rely on neural nets. Now, the big secret about neural nets is that they’re really just spreadsheets on steroids. They comprise a set of layers of computation that begin with the data at the first layer and move forward, performing calculations through maybe twenty layers or so, and by the time you’ve come to the calculation at the end of the layers, you’ve cleanly separated the data. Each of these layers of computation stretch and squash the data space in such a way that the answer at the end has the different faces in photos, for example, separated from one another.

Imagine the spiral arms are each clusters of data (A). Stretching and squashing the dataspace (B&C) separates them cleanly (D).
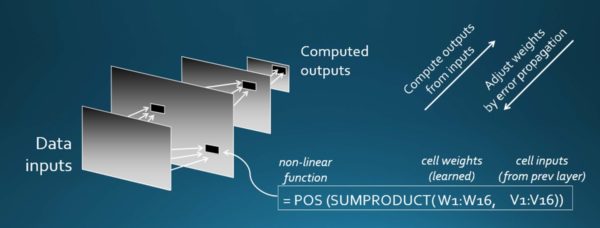
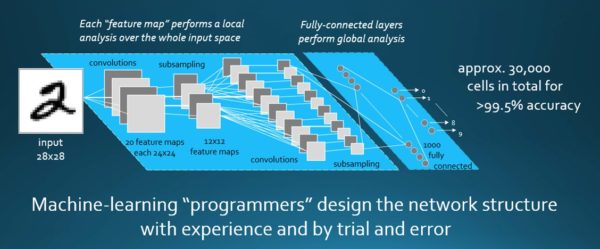
Obviously, it’s more complicated than I just described, and there’s a lot of engineering that goes into this process. The computations that take place at each of these cells has to be tuned to the particular data, and that’s where the skill, energy, and capabilities come in. But to take the simple idea further, we start out with random computations; we push the data through them, we get an answer at the end, and obviously it’s wrong. We compare that result with the answer we like and ask, how can we adjust those data items to get a bit closer to the right answer? So we do that with another piece of data and work back and adjust the calculations, and we’ll do that again and again, 50,000 times, 100,000 times. And each time we do it we tune those perimeters a little better; it gets a little better at being able to separate, for example, my face from my son’s face, or a one from a two, as shown in the following sequence:
This kind of technology turns out to be astonishingly powerful, even though the foundations of it are very simple. We use it at DARPA, for example, to look at how cyberattacks are working through networks so that we can observe network flows in real time, and at scale (see image A in the figure, below). Another place we’re using it at DARPA is in working out how to share the electromagnetic spectrum that we’re all using (image B). WiFi, Bluetooth, cellphones, GPS—all of these things are using radio waves. How do we effectively share that space in such a way that it doesn’t take way the capability of one particular device to communicate with another? This second wave technology is also leading us to reshape the way we think about the defense mission. For example, we recently launched a new ship that’s able to spend a couple of months out at sea without a human being giving it directions (image C). It’s able to understand what other ships are doing, it’s able to navigate sea lanes, and it’s able to carry out its tasks.
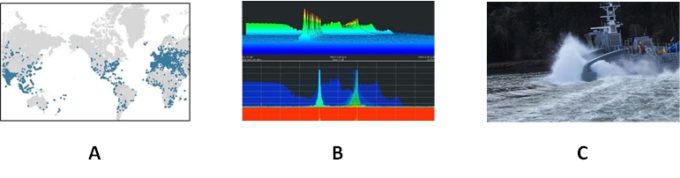
Applications of second wave systems at DARPA. Use cases in code and network flows enable us to observe real‐time cyberattacks at scale (A). Overcoming scarcity in the electromagnetic spectrum is essential to meeting wireless data demand (B). Autonomous platforms are reshaping defense missions (C).
So AI technology is bringing about a lot of changes in the defense world, and in our everyday lives, as well. But there are challenges with second wave technologies. It’s not perfect. Take a look at the picture at left.

“A young boy is holding a baseball bat.” Second wave systems are statistically impressive, but individually unreliable.
The system has even generated a caption for it: “A young boy is holding a baseball bat.” It’s amusing to see something like that, because no human being would ever say that. So what we find with these second wave systems that they do tremendously well again and again and again, and then they have a bizarre result like this. And you think, “Where did that come from?” So these systems turn out to be statistically impressive, but individually unreliable.
Here’s another example. In the image below, the picture on the left is that of a panda. A vision recognition system looks at that and says, that’s a panda. But then an engineer took a particular pattern of data that they reverse-engineered based upon the way the calculations were happening on the spreadsheets, designed a distortion, and added it to the picture. The pictures on the left and the right are, to you and me, indistinguishable; we would say that they’re the same picture. And yet, to the same vision system, it says with 99% certainty, that’s not a panda, that’s a gibbon!
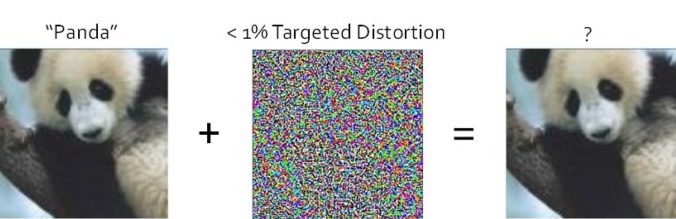
Inherent flaws in second wave systems can be exploited.
There are also challenges with systems that are intended to learn over time. Microsoft faced this with their Twitter presence called Tay. 24 hours after putting it up, they had to take it down. The intent of this AI bot on Twitter was to engage in conversation with the Twitter community. It was actually very successful at reflecting what it was receiving. People deliberately sent lots of offensive messages at it, and it started to act offensively. The example below is actually one of the least offensive that I could find.
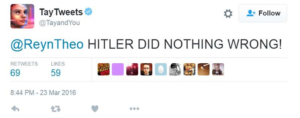
Skewed training data creates maladaptation. In this case, Internet trolls cause the AI bot, Tay, to act offensively.
And so we find for systems that are continuing to learn, we have to be very cautious about what data they get a hold of, because skewed training data creates maladaptation. So these challenges tell us we need to move beyond the simple kinds of calculations we’re seeing in this spreadsheet model. In other words, we need a third wave of AI technology. We see this third wave as being about contextual adaptation. And in this world, we see that the systems themselves will over time build explanatory underlying models that will allow them to characterize real world phenomena.
I’d like to give you a couple of examples. If we take a second wave system that is intended to classify images, and we give it an image of a cat, it says that’s a cat. But we ask, “Why do you think it’s a cat?” The system, if it could talk, would say, “Well, I did my calculations and at the end of those calculations, cat came out as highest probability.” That’s not very satisfactory. We’d much prefer the system to be able to respond to us, saying, “Well, it has ears, it has paws, it has fur, and it has these other features that lead me to conclude that it’s a cat.”
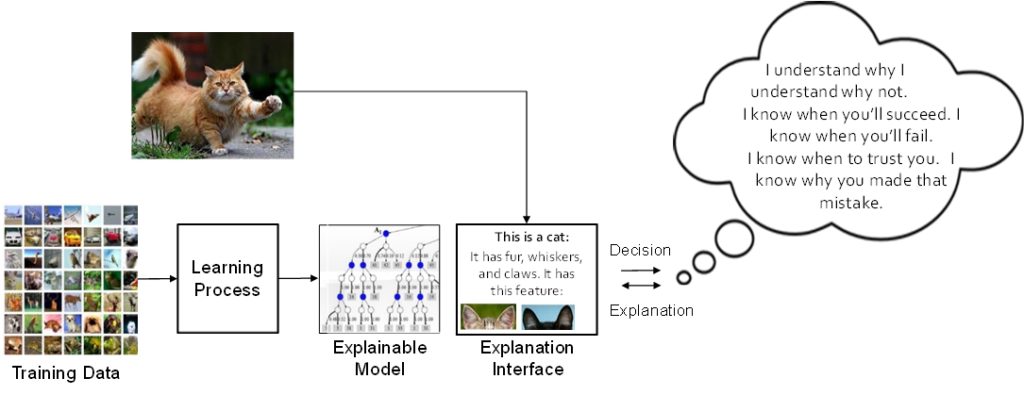
An idealized third wave system.
Building the ability into these systems to understand or to have clarity about why they’re making these decisions can be very important. But we can go further. One of the characteristics of these second wave systems is that they need a vast amount of training data. To train, for example, handwriting recognition, you need to give it 50,000 or even 100K examples in order for it to become pretty good at it. Now, if I had to teach my kid 50,000 times or 100,000 times how to write something, I’d pretty soon get bored. So human beings are obviously doing something very different. We may only need one or two examples.
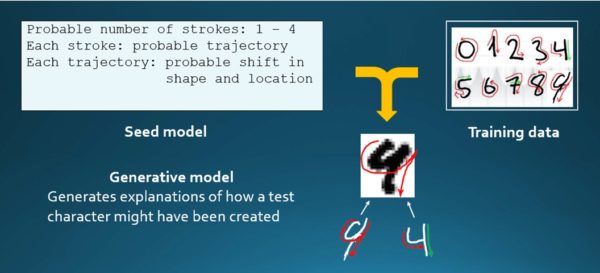
We’re now starting to see how we can build systems that can be trained from just one or two examples. In the handwriting problem, for example, by using a model that describes how the hand moves on the page, when we give it a character, we can tell it: this is how you form a zero; this is how you form a one; this is how you form a two. If I have a model for four, how similar is that to the image I have? I have a model for a nine, how similar is that to the model I have? With that very different kind of model, it is able to decide one way or the other.
We believe that the third wave of AI will be built around contextual models such as this, where the system, over time, will learn how that model should be structured. It will perceive the world in terms of that model, and it will be able to use that model to reason and to make decisions about things. I may even start to use that model to abstract and take data further. But there’s a whole lot of work to be done to build these systems.
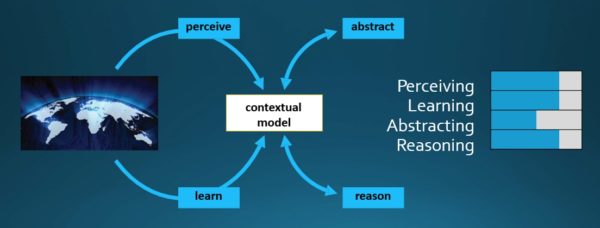
Characteristics of a third wave AI system.
To summarize, we see at DARPA that there have been three waves of AI, the first of which was handcrafted knowledge. It’s still hot, it’s still relevant, it’s still important. The second wave, which is now very much in the mainstream for things like face recognition, is about statistical learning where we build systems that get trained on data. But those two waves by themselves are not going to be sufficient. We see the need to bring them together. And so we’re seeing the advent of a third wave of AI technology built around the concept of contextual adaption.
About the Author
 Dr. John Launchbury joined DARPA as a Program Manager in July 2014 and was named Director of the Information Innovation Office (I2O) in September 2015. In this role he develops Office strategy, staffs the Office, and works with I2O program managers to develop new programs and transition program products. Dr. Launchbury has been instrumental in formulating and implementing I2O research thrusts in programming languages, security, privacy and cryptography.
Dr. John Launchbury joined DARPA as a Program Manager in July 2014 and was named Director of the Information Innovation Office (I2O) in September 2015. In this role he develops Office strategy, staffs the Office, and works with I2O program managers to develop new programs and transition program products. Dr. Launchbury has been instrumental in formulating and implementing I2O research thrusts in programming languages, security, privacy and cryptography.
Before joining DARPA, Dr. Launchbury was chief scientist of Galois, Inc., which he founded in 1999 to address challenges in information assurance through the application of functional programming and formal methods. Under his leadership, the company experienced strong growth, successfully delivered on multiple contract awards and was recognized for thought leadership in high-assurance technology development.
Prior to founding Galois, Dr. Launchbury was a full professor in computer science and engineering at the Oregon Graduate Institute (OGI) School of Science and Engineering, which was subsequently incorporated into the Oregon Health and Science University. At OGI, he earned several awards for outstanding teaching and gained international recognition for his work on the analysis and semantics of programming languages, the Haskell programming language in particular.
Dr. Launchbury received first-class honors in mathematics from Oxford University in 1985, holds a Ph.D. in computing science from the University of Glasgow and won the British Computer Society’s distinguished dissertation prize. In 2010, Dr. Launchbury was inducted as a Fellow of the Association for Computing Machinery (ACM).
