

Authorship attribution is not a new trend in human history, nor is it a problem only of recent years.
With the spread of literacy, questions of authorship attribution have been raised as early as at the dawn of the last millennia. However, the sense of urgency and demand for high-end technology in attributing authorship has only been increasing—and much more so in the past century.
It becomes clear why the problem had remained unresolved, if one addresses the intricacy and complexity of the task at hand. It lies in the ability to assess and define the features that compose a writing style of any particular author, and then becomes more complicated by the colossal number of authors, each having the same or different features and components of a writing style. The next obstacle is the actual transmission of the processed data into a natural language processing (NLP) technology.
Our team of researchers, scientists, and engineers has come to the question of authorship attribution with the purpose of overcoming the stated obstacles and surpassing the previous achievements. It was our objective to create a technology that could:
- Attribute authorship without a dependence on genres or styles.
- Determine characteristic features of any author using a minimal training set.
- Attain a high level of accuracy.
The system that’s being presented in this article has reached these objectives and has been accepted by scientific circles as a state-of-the-art technology of never-before achieved accuracy.
Below is our account of how we were able to overcome the challenges and to develop an authorship attribution system that works with precision and effectiveness.
Underperforming Predecessors
Previous models of authorship attribution systems have been unsuccessful or only partially successful due to a common stumbling block in the authorship field: creating the right classifiers for each author, which basically translates into its ability to spot and evaluate the features of each author’s identity. The problem was exacerbated when different writing styles or formats were inserted into the picture: they confused the technology, thus contributing to low accuracy rates.
This fundamental difficulty was not the only one in the pursuit of the correct attribution of authorship.
Systems needed extremely large volumes of texts to analyze one author, and could only handle a limited number of authors, showing its optimum result at three or four authors. Whereas when the system attempted to identify authorship of larger numbers of authors, the accuracy of the results dropped to a meagre 55%, which could not serve as a reliable outcome.
All of the above combined to impose a roadblock in authorship attribution, and until now, there were no solutions that satisfied the scientific community’s needs.
We applied the core techniques of stylometry (study of linguistic style dating back to 15th century) to our technology and, combining it with NLP, have arrived at Artificial Intelligence on the basis of machine learning that produced the following results:
- Accuracy level of 85%.
- Ability to operate on minimal number of texts.
- Increase in number of processed authors to 20.
Model of Authorship Attribution System
As a result of our research and development, we have been able to combine NLP, Feature Engineering, Feature Selection, and Machine Learning in such a way that has resulted in the technology with high accuracy.
Figure 1 shows the model of this system.
The system needs training sets of N number of authors with texts that were written by those authors and were not altered in any way.
During the feature engineering stage, we have converted text to feature vectors. During feature selection stage, we have reduced feature vectors dimensionally.

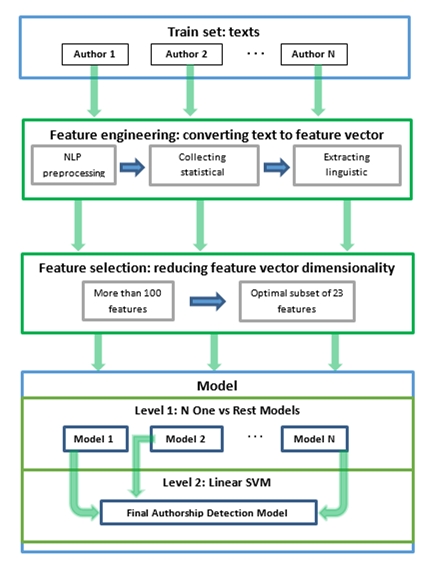
Figure 1. Model of new system of authorship attribution.
Results of Authorship Attribution System Performance
Table 1. The results of authorship attribution system performance.
| 20-Fold Cross Validation | |||
| Precision | Recall | F1 | |
| Dataset0 | 0.8597 | 0.7297 | 0.7894 |
| Dataset1 | 0.8568 | 0.7068 | 0.7746 |
| Dataset2 | 0.8705 | 0.7205 | 0.7884 |
| Dataset3 | 0.8694 | 0.7394 | 0.7991 |
| Dataset4 | 0.8534 | 0.7434 | 0.7946 |
| Dataset5 | 0.8801 | 0.7680 | 0.8202 |
| Cross Validation LOO | |||
| Precision | Recall | F1 | |
| Dataset0 | 0.8498 | 0.7297 | 0.7852 |
| Dataset1 | 0.8520 | 0.7120 | 0.7757 |
| Dataset2 | 0.8652 | 0.7252 | 0.7890 |
| Dataset3 | 0.8493 | 0.7413 | 0.7916 |
| Simplified LOO | |||
| Precision | Recall | F1 | |
| Dataset0 | 0.9333 | 0.9222 | 0.9277 |
| Dataset1 | 0.8939 | 0.7955 | 0.8418 |
| Dataset2 | 0.8647 | 0.7547 | 0.8060 |
| Dataset3 | 0.8506 | 0.7606 | 0.8031 |
| Dataset4 | 0.8757 | 0.7557 | 0.8113 |
| Dataset5 | 0.8498 | 0.7725 | 0.8093 |
In our work, we have created six datasets to allow us to perform a comprehensive assessment of the accuracy of the system:
Dataset0 – contains 15 authors, with 37 texts
Dataset1 – contains 15 authors, 191 texts
Dataset2 – contains 15 authors, 848 texts
Dataset3 – contains 15 authors, 1554 texts
Dataset4 – contains 15 authors, 2440 texts
Dataset5 – contains 15 authors, 4896 texts
Table 1, above, shows the results that Authorship Attribution System has produced during the performance tests.
Precision and Recall are two common metrics used to evaluate the performance of most of the systems working in data extraction.
Precision is a fraction of relevant instances among the retrieved instances. It shows how many of the identified documents were identified correctly.
Recall is a fraction of relevant retrieved instances among the total amount of relevant instances. It shows how many of the total number of a specific type of documents were identified correctly.
Types of answers that the system delivered:
True Positive – when the system correctly attributed authorship to the author
False Positive – when the system incorrectly attributed authorship to the author
True Negative – when the system correctly identified that the text does not belong to the author
False Negative – when the system incorrectly identified that the text does not belong to the author
Thus:
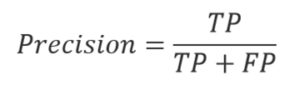
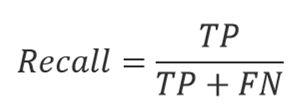
On the basis of these two metrics, we are able to calculate F1 score, which is a measure of a test’s accuracy. It takes into account both Precision and Recall, and can be interpreted as a weighted average of both measures.
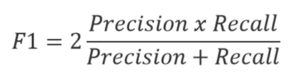
F1 score is also called a harmonic mean of precision and recall, as the formula gives them an identical weight. It is possible to give more weight to either precision or recall, in which case the formula would look this way:
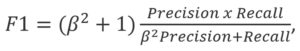
Where β gives more weight to Precision if 0<β<1; or β gives more weight to Recall if β>1; or F1 becomes balanced if β=1.
To calculate the test results, three methods are used: K-fold Cross-Validation, Simplified LLO, and LLO. The methods differ depending on how the data was partitioned into training and test sets.
The cross-validation algorithm called Leave One Out (LOO) is one of most consistent ones, proving the same results. This algorithm is independent from the parameter seed, but it has an essential drawback of an extremely high computational complexity. It requires the system to be trained on all other data before testing it on the given example.
Our team has also used a method called Simplified LLO. At the start, it converts texts into feature vectors that in turn create a features matrix, without calculating them again. The matrix is used to train the model, while each sequentially selected vector is used as a test sample. The average of all examples is then calculated to the accuracy of the model, the same way as LLO. The difficulty with this method is that it sometimes may cause overfitting, but the influence of it is small when using large corpora.
In our early experiments we used the classic value K=5 in Cross-Validation, however, for smaller sets of data (Dataset0, Dataset1), due to such a small value of K, a certain part of classes turns out to be in a training set, with another part in a test set. It significantly influences the statistics. Thus, it was decided to use the value of K that would be larger than the number of authors. The value K=20 does not fully prevent the case when an author is not presented in a training set at all, but gives a close approximation.
Opportunity to Try Out the Technology
At the moment, the algorithm is being further optimized, but we have finished the initial development of the product.
We’ve dubbed the system Emma, and released it to a common audience in beta. Presently, Emma’s interface has been gamified to make the interaction with it more dynamic.
The first step in the game is to teach Emma. For that, the system needs to receive a text file(s) with no less than 5,000 words of a 100% original text written by one author, in English. The next step is the testing conducted on new texts that may or may not belong to the trained author. Users will be able to see whether Emma got it right or not.
There are several rules that players should follow to allow the algorithm to show its potential, and to eliminate the possibility of errors originating from compromised texts used in training.
If the text was translated or edited in any way by a third party, such text is considered to be compromised, as the features of the original author may have been removed or tampered with by another person, who becomes a contributor to the text, enriching it with his or her own writing identity.
After the training is done, the next step is the authorship attribution per se. That’s when Emma will either confirm or disprove the text to be written by the trained-upon author.
More Details
For the first time in the history of authorship attribution, precision of results has reached high levels. We would like to invite enthusiasts and researchers of machine learning and NLP to join our community at emmaidentity.com and experience the system in action.
To all those interested in more details about the technology, its methodology, and implementation, we would be happy to oblige in our next reviews.
About the Author
Oleksandr Marchenko is a Professor of Computer Science, the author of more than 80 research papers, Emma’s Creator and CEO. He also leads the team behind Unicheck—fully functional plagiarism detection software for higher education and K-12. His interests include artificial intelligence, natural language processing, and machine learning.
