

Artificial intelligence has been a dream and a goal of computer science for quite some time. Throughout the decades there have been several advances in capabilities, research, and understanding of the topic. Applications were even developed and deployed. After most of these advances, however, the initial enthusiasm gave way to disappointment and assorted opinions about the factual impossibility of the task at hand.
You may remember Deep Blue beating Garry Kasparov at chess, and may wonder about how long ago that happened. Were any practical applications for real-world problems created? We can still say that it was a great breakthrough in improving the methods and capabilities used at the time, but the payout was short-lived. And if we go further back in time, we can see a pattern: a breakthrough in AI, some hype, some funding, development, sometimes deployment, and then a sudden drop in activity and excitement. A valley of disillusionment. We’ve come to call those extended periods of nothingness “AI winters.”

World chess champion Garry Kasparov during game six of the match against IBM’s Deep Blue , May 11, 1997.
The reason for those winters are fairly clear. A common pattern emerges wherein a promising break- through was usually followed by great disappointment, which dampened the possibilities for new funds and investing. Let’s discuss an example. In 1954, a Georgetown-IBM experiment demonstrated the successful translation of sixty Russian sentences to English. At the time, automatic translation from Russian to English was a sweet spot, as the United States and Russia were in the midst of the Cold War. The demo was considered very successful— the sixty sentences were fed to the algorithm and the translation was perfect. This triggered funding for a generalized automated approach of translation from Russian to English.
Many companies and agencies tried to tackle this daunting challenge and failed miserably. One way to assess the capabilities of translation is to do it in a whole circle, back and forth from the origin to the target language. In this case, a phrase in English would be translated into Russian, and the Russian translation would then be translated into English.

The public demonstration of a Russian-English machine translation system in January 1954—a collaboration of IBM and Georgetown University. The experiment involved just 250 words and six rules of grammar, but it raised expectations of such systems.
In most of those systems, when fed the phrase, “The spirit is willing, but the flesh is weak” to translate into Russian and back to English, the output would be akin to “The whiskey is strong, but the meat is rotten.” It might seem that for a syntactic word-for-word translation, the result is not that bad, but imagine trying to translate a whole letter or book—the result would be so scrambled it would not make sense. In the end, the automated translation could not be trusted, not beyond a novelty and definitely not for sensitive matters.
This example shows the type of disillusionment faced when trying to tackle complex challenges without the proper means and conditions. Why did this failure happen? Because a carefully crafted and constrained AI system worked very well within the boundaries and context for which it was built. But as soon as it was tested outside those boundaries, it failed completely.
The application side of the failed experiment was one component in the resulting lack of trust in the technology. On the technical side, there were concerns, as well.
When the first artificial neural networks (ANN) were created in 1958, in the form of the perceptron (or an NN with one hidden layer), it was mathematically impossible to generate an exclusive-or (XOR) logic, laying waste to the potential of the technique. Furthermore, there was influential research by Marvin Minsky and Seymour Papert in 1969 that exposed two main problems with ANN at that time. The first was the one we just described; and the second was that computers didn’t have enough processing power to effectively handle the work required by large neural networks.
By 1975, the process of backpropagation was invented, making it possible for ANNs to learn multilayer models, or solve the XOR problem. But then the problems of vanishing gradients (the inability to learn on deep representations), shift variance, and intolerance to deformations arose. And so the story goes.
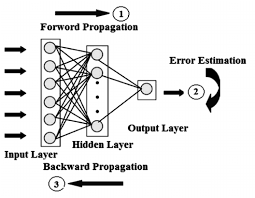
Backpropagation—one of deep learning’s great breakthroughs—enables network learning by iteratively adjusting the weights of a neural network in order to minimize the error between the model’s prediction and the ground truth on which it is based.
After this history, you might be wondering, why support AI now? What if an AI winter were to drop down upon us again? If these types of boom-and-bust cycles have happened several times in the past, why should we invest and bet on AI this time?
We’ll explore the conditions, along with many prominent cases, that make us believe the cycle is broken and the winters are gone for good.
***
Now that we’ve seen how the AI winters evolved in the past, we will explore the changes and conditions that make artificial intelligence a suitable and sustainable technology moving forward. What are those conditions?
Let’s think about the different dimensions that work as enablers of artificial intelligence: data, processing power, access, and technical prowess.
On the data front, we live in a radically different world from that of decades past in at least two ways. Internet ubiquity is one. The mobile revolution is the other. Billions of devices are connected to the web—not just laptops and desktop computers, but also phones, cars, home-assistant devices, and many others.
Available data sources (very active ones at that) broadcast all sorts of information about their users and their workings. Furthermore, Internet of things (IoT) devices close the loop, acting as both sensors and actuators, bridging the gap between the digital and the physical.
This means that on a daily basis the amount of data generated, processed, stored, and made available is getting bigger, faster, and more varied. This trend does not show any sign of slowing down. In fact, it’s accelerating. You can think of what is called Zuckerberg’s Law, or the Social Sharing Law, as the counterpart of Moore’s Law, stating that people are expected to share twice as many “things” (status updates, pictures, interactions, etc.) every year over the prior one.
To handle that, we have storage that is cheaper than ever, bigger than ever, and all kinds of tools that enable managing all that data at the required speed and handling all the different varieties of data, which are ever more available and mature.
This enabler actually has a name, one that has been a buzzword of its own for several years now. Does Big Data ring a bell?
Let’s visit the processing power now. Deep Blue was, physically speaking, a huge supercomputer. The first time it played chess again Kasparov, it actually failed. For the rematch, a lot of computing power was added. The lads at IBM, with deep pockets, were able to develop that monstrous machine, but it’s hard to imagine a small garage start-up being able to invest all those millions to build something like that—or a couple of independent researchers, or a small experimental unit within another business.
Nowadays, graphics processing units (GPU) are available at a reasonable price if you want to set up an in-house server to do some sort of AI. The same way that many big data developments tackled commodity off-the-shelf (COTS) hardware, pursuing high-performance computing, AI shifted to leveraging graphic cards (Nvidia being the major player). They were developed for the throughput requirements of graphics rendering and became a cheap way of accessing an enormous parallel processing capacity.
This was followed by the advent of cloud computing, which enabled everyone to access an AI-ready infrastructure in a very cost-efficient way, paying as they go, instead of buying lots of hardware (and lowering the entrance barrier to that kind of hardware by not needing to know how to set up a private cluster). Combined with GPUs, you could access a whole array of high-performance servers for a very competitive price.
In terms of access and technical prowess, we can see the open source movement has achieved an incredible level of maturity and reach. It has allowed access to everything from languages, tools, frameworks, and libraries to online courses and materials, as well as the interplay between academia and open source, building upon and sharing each other’s improvements. Tools like TensorFlow, Python, Torch, CNTK, Anaconda, Jupyter, R, and more, make the development and training of algorithms much simpler.
Big tech players are investing heavily in the development of artificial intelligence components that can be leveraged to build “powered by AI” solutions, with such familiar names as IBM’s Watson, Microsoft’s Azure Cognitive Services, Google Cloud Platform Machine Learning Services, Amazon ML, Dialogflow (previously known as Api.ai), and so on.
With such a promise of economic benefit with reduced amounts of risks, many are investing heavily in the advancements of AI and adopting AI solutions. And the bet is paying off, as many companies are using artificial intelligence not as merely a novelty to show off, but to successfully drive core processes for them. The hype cycle became a virtuous one.
All the aforementioned conditions are strong indicators that artificial intelligence is here to stay, and that practical applications of the technology can be leveraged with a huge side note: artificial intelligence has the power to disrupt business in many layers. We can either grow with it or get displaced from the ecosystem altogether.
On the flip side, this explosion has brought myriad start-ups and initiatives competing on value propositions, approaches, and use cases. We are indeed experiencing an artificial intelligence gold rush, with an emergent structure yet to appear.
 This article is excerpted from the forthcoming book, Embracing the Power of AI: A Gentle CXO Guide.
This article is excerpted from the forthcoming book, Embracing the Power of AI: A Gentle CXO Guide.
About the Authors
Javier Minhondo
Javier is a devoted and passionate software engineer with years of experience. As the vice president of technology of the Artificial Intelligence Studio at Globant, he engages with companies to enhance digital journeys by leveraging cognitive and emotional aspects with the ever-increasing capacity of machines to learn and understand complex patterns. He utilizes state-of-the-art techniques, including deep learning, neural networks, or traditional machine learning approaches, coupled with hacking and engineering abilities.
Juan José López Murphy
Juan’s primary area of interest is working on the intersection of innovation, strategy, technology, and data. He is passionate about data, whether from a data science, data engineering, or BI data visualization mind-set, always looking for the ways in which technology enables and is the driver of business model innovation—true disruption is the result of both.
Haldo Spontón
Haldo is an eager technology and math lover, with vast experience as a teacher and researcher in signal processing and machine learning. He’s part of the leadership team of our Artificial Intelligence Studio at Globant. He’s focused on the usage of AI algorithms in end-to-end applications, combining user experience, business needs, and technology innovation.
Martín Migoya
In 2003, Martín, with only a small start-up capital, co- founded Globant with three friends. Fifteen years after its launch, Martín drove the company as CEO from a small start-up to a publicly listed organization with more than 6,700+ professionals, pushing the edge of innovative digital journeys in offices across the globe. Martín, whose passion is to inspire future entrepreneurs, frequently gives lectures to foster the entrepreneurship gene, and has won numerous prestigious industry awards, including the E&Y Entrepreneur of the Year award.
Guibert Englebienne
Guibert has had a lifelong passion for cutting-edge technology and exploring how it fits into business and culture. He is one of Globant’s cofounders and now serves as CTO leading the execution of thousands of consumer-facing technology projects. He is a frequent speaker and thinker on how to drive a culture of innovation at scale in organizations. Guibert is widely recognized as one of the industry’s most influential leaders.

